Guest Post – Navigating the Drift: Persistence Challenges in the Digital Scientific Record and the Promise of dPIDs – The Scholarly Kitchen
[ad_1]
Editor’s Note: Today’s post is by Christopher Hill, Philipp Koellinger, and Erik van Winkle. Christopher is a neuro-economist, technologist, and entrepreneur. He co-founded DeSci Labs, developing next-generation technologies to promote replicable, open, and FAIR scientific publishing. Philipp is a professor of Economics at Vrije Universiteit Amsterdam. He co-founded DeSci Labs and serves as the president of the DeSci Foundation. Erik Van Winkle is the head of business development for DeSci Labs, FAIR Implementation facilitator for the GO FAIR Foundation, and the lead of the dPID Working Group for the DeSci Foundation. Full disclosure: The authors are affiliated with DeSci Labs AG and the DeSci Foundation. dPID is an open-source software solution distributed under an MIT license, developed by DeSci Labs AG (https://github.com/desci-labs/nodes/).
Persistence on the Internet: A Global Problem
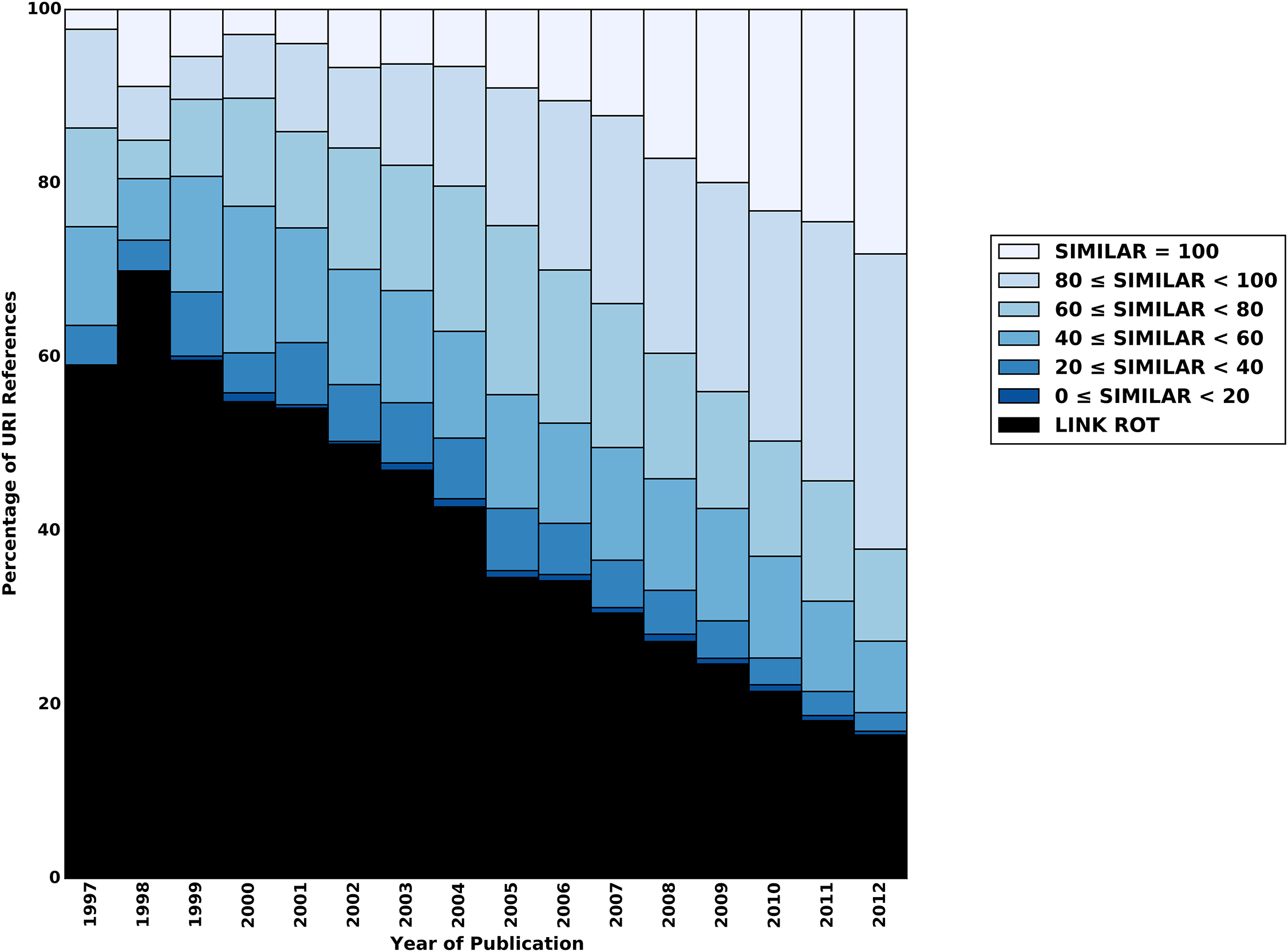
We all agree that we need a digital version of the scientific record. The problem is that the current Internet was not designed for this purpose. Beyond the issues of broken links, there is the problem of content drift, where the URL resolves but is no longer linked to the initial content. A study by Jones et al. (2016) shows that link rot or content drift affects almost all Internet references in the corpus of Elsevier, arXiv, and PubMed Central. The older the reference, the more severe the problem gets. URLs from 1997 are hardly ever valid nowadays (see Figure below). But even 50% of URI references just three years old are affected by link rot and content drift.
In this post, we discuss current approaches to addressing the shortcomings of the existing Internet technology, identify remaining bottlenecks, and suggest how they could be resolved. The upgrades to the backbone of the scientific record we discuss here would go a long way toward addressing the replication crisis and the increasing challenges for publishers to spot fake research.
Persistent Identifiers: Challenges for DOIs
Of course, persistence problems on the internet are well known. The solution is persistent identifiers (PIDs) for digital content, which are supposed to enable long-lasting references and access. The Digital Object Identifier (DOI) system was developed as the PID solution for the digital version of the scholarly record — and it’s a huge success story.
DOIs have emerged as the de-facto standard of persistent identifiers for scholarly information, up to the point where some people think DOIs are guarantees for legitimate science (they are not). Over 100 million DOIs have been registered for publications, pre-prints, scientific datasets, and other academic content. DOIs are crucial for academic databases and indexing services such as the Web of Science, Scopus, Dimensions, etc.
However, our current gold standard for identifying and resolving scholarly content is still falling short of the desired level of persistence. A truly persistent identifier should always resolve to the same result. But that’s not the case for DOIs. According to a study by Klein and Balakireva (2020), approximately 50% of DOI requests fail to resolve to their target resource. The study details how DOI behavior is inconsistent across different networks: You may get very different responses when trying to resolve a DOI from your computer at work and your mobile phone when traveling.
Obtaining DOIs and updating the DOI record is also a tedious and expensive task for publishers. Both CrossRef and DataCite have fee structures that charge more money if more DOIs are created. If the URL of a publication changes, the DOI publisher is responsible for updating the DOI database — and not all of them do so consistently and quickly. In other words, the DOI system relies on social contracts and trust between platform operators and PID providers that are difficult and expensive to enforce. This limits both the reliability and the scalability of the DOI system.
Moreover, in a potential future world of FAIR (Findable, Accessible, Interoperable, and Reusable) science, every research artifact – not just the published manuscript – will need a globally unique, persistent, and resolvable identifier. Trillions of PIDs must be minted over the next decade to achieve that goal, and trillions of PID-to-URL mappings will need to be maintained. This is inconceivable with the current DOI system.
The prevalence of link rot, content drift, artifact fragmentation, and inconsistent resolution is poised to expand alongside this explosion of (or worse, lack of) DOI minting. The social costs of not embracing FAIR science are even worse: A study on behalf of the European Commission found that the annual cost of not having FAIR research data to the European economy alone is more than €10 billion every year. This estimate does not even include the adverse effects on research quality, technological progress, and slowed economic growth.

dPID: Distributed Architectures for Distributed Ecosystems
Technological solutions to these problems have already been developed, but have yet to be widely implemented within the scientific ecosystem. Over the past two decades, several open-source communities and W3C working groups have addressed the root causes underlying the lack of persistence on the Internet. The core idea is that PIDs should not ask, “What is the content stored at this location?” Instead, the right question is, “What is the content with this digital fingerprint?” A minor tweak to such a foundational question has far-reaching impacts, enabling deterministic resolution.
Deterministic resolution is the idea that PIDs should be guaranteed to resolve to their indexed resource. Deterministic resolution has long been an elusive goal, but it is finally in sight due to the maturity of enabling technologies. This new class of PID technology is called “dPIDs” – short for “decentralized persistent identifiers.” Beyond deterministic resolution, dPIDs offer many surprising and beneficial properties that could substantially improve how science is done, communicated, and evaluated.
The act of minting a dPID enables making the underlying content available on an open peer-to-peer network where repositories, libraries, universities, and publishers can participate in curating and validating content. It also makes it possible to store redundant copies with the same identifier on different servers operated by various entities without developing or using API-based services. It also eliminates the need to maintain and update DOI records manually. dPIDs also provide a graceful way to handle the data transition to a new host when a repository or journal is scheduled to go offline or changes owners because the link to the content does not change, thus adding a built-in way to safeguard content that is otherwise at risk of being lost forever.
dPIDs are not just identifiers for a single file. Instead, they allow addressing linked folder structures that scale nearly indefinitely. Each file in this folder structure can be uniquely addressed from the base dPID, enabling digital research objects that link all relevant project pieces together (e.g., manuscripts, data, code). dPIDs are also built to be versionable, meaning that indexed content can change over time, without overwriting the original version. Changes are logged, timestamped, and digitally signed by the PID owner, providing traceable and verifiable provenance for any modifications performed to a PID, while ensuring that previous versions of the content remain equally resolvable.
Versionability and provenance of dPIDs enable researchers to create a transparent track record of how they arrived at their final results, which would be aligned with best open science practice and help to address the replication crisis and the flood of fake research that poses substantial challenges for publishers. Instead of just seeing the submitted version of a manuscript, editors, referees, and readers could also see the entire history leading up to that manuscript, including time-stamped versions of analysis plans, data, code, lab notes, early drafts, etc.
Persistent resolution also enables scientists to retrieve open datasets directly via dPID into their programming and computing environment with a single line of code or, alternatively, to send a containerized compute job to the servers that host the data. This latter technology is called edge-computing and is especially valuable for sensitive datasets that cannot be publicly shared or for extremely large datasets: For example, downloading 1PB (e.g., climate modeling data) can cost over $100,000 in egress fees and take several months even under optimal conditions – a prohibitive burden even for very well-funded scientists.
While technically simple to implement, adopting and scaling a new public infrastructure such as dPIDs is difficult in a vacuum. Fortunately, the community has done extraordinary work with ORCID and RoR as identity layers for scientists and their organizations. Because we can build on existing identity solutions, adopting dPIDs does not need to start in a vacuum: we can both re-use existing infrastructure and benefit from its pre-existing network effects.
Additionally, trustworthy provenance combined with the open nature of the network would enable journals, libraries, or data stewards to add new information to enrich research objects over time. These dPID data enrichments could vary widely in their nature: from FAIR metadata (e.g., ontologies and controlled vocabularies), open peer-review reports, digitally verified badges for open data, reproducibility, and much more. This has many benefits, including creating better metrics and incentives for open science practices. Furthermore, since reading and writing on this content addressable network is without specific charges, equitable access is ensured, and substantial cost savings can be realized.
Compatibility of dPIDs and DOIs
It’s important to note that dPID is a new PID technology, not a new PID standard. The distinction is important because a proliferation of PID standards is not desirable. In fact, DOIs can be “upgraded” to become dPIDs by adding a DOI as a synonym to a dPID. DOIs would then simply resolve to a resource linked to a dPID filesystem. This backward compatibility would not only get rid of the need to update DOI records manually and make DOIs actually persistent, but it would also unlock the new capabilities described above. A single DOI could unfold into an entire file system with individual PIDs for machine-actionable digital objects and resolve deterministically to their mapped resource.
Beyond these properties, dPID technology can help to preserve the freedom and sovereignty of all stakeholders in the scientific ecosystem. Platform operators, repositories, publishers, and libraries maintain control over the content they share publicly. Importantly, dPID technology is entirely based on open-source software that anyone can run for free on their own hardware.
dPID has garnered much interest in the persistent identifier community. International Data Week 2023 saw the formation of a dPID Working Group with diverse participants from organizations around the globe. This group, hosted by the DeSci Foundation, aims to act as a driving force, community hub, and shared knowledge base and is open to anyone interested in participating.
Realizing the ideal of a fully machine-actionable scientific record is more critical than ever. While the importance of scientific data as a primary output of research is rising and data volume is increasing rapidly, interoperability needs to catch up. With the rise of AI and fake science, a trustworthy track record of a manuscript’s origin and context is invaluable. Given their properties, dPIDs and the deterministic resolution they provide are paths worth exploring.
The Tech Stack behind dPIDs
For those who would like to dive into the technical details, here is a brief overview of the core technologies that dPIDs are built upon. These protocols and software-based solutions have already been developed alongside their W3C formal specifications. They are free to use and open-source, enabling anyone to participate in further improvements.
- IPFS allows you to share and access data by content identifiers. Content hashes are used to identify and resolve each file. IPFS forms a peer-to-peer storage network of content-addressed information, allowing users to store, retrieve, and locate data based on a digital fingerprint of the actual content. This fingerprint is generated by a cryptographic hash function (e.g. SHA-256), which converts any content into a fixed-length string. Changing anything in the content (i.e. a single word, pixel, comma) will yield a different hash. SHA-256 allows generating 1077 different hashes, which is billions of times more than the number of atoms on Earth. Thus, the probability of two different inputs yielding the same hash is near zero. Because all data is guaranteed a unique fingerprint, content drift cannot happen because that would be accessible under a different fingerprint. Furthermore, it’s easy to check if the content you received from the IPFS network matches its hash, eliminating the risk of downloading content from unknown network peers. And thanks to IPLD, IPFS works not only with files but also with arbitrary data structures. This ensures the persistence of relations between artifacts such as manuscripts, data, code, or other PIDs for organizations and people. It also creates the possibility of mitigating the scientific record’s fragmentation and getting much better metadata and analytics.
- Decentralized Identifiers. Decentralized Identifiers (DIDs) enable verifiable, decentralized digital identity. A DID can refer to any target (e.g., a person, organization, thing, data model, abstract entity, etc.) as determined by the controller of the DID. The design enables the controller of a DID to prove control over it without requiring permission from any other party, allowing trustable interactions.
- Blockchain technology creates persistent recording. A blockchain is a distributed ledger with a growing list of records (blocks) securely linked via cryptographic hashes. Smart contracts associated with blockchains autonomously record the root hash of an IPLD folder structure on this cryptographic ledger, along with a time stamp and the ID of the person or entity who updated the record, creating highly persistent, open, and trustworthy metadata.
For those interested in the dPID Working Group mentioned above, newcomers are always welcome, and those interested can reach out to info@descifoundation.org.
[ad_2]